Способы составления семантического ядра

Семантическое ядро (СЯ) – это основа практически любого сайта. Именно с его составления и анализа надо начинать любой проект. Способов собрать его – множество. Ниже я расскажу о тех, которыми когда-либо пользовался сам, дам краткий анализ каждого из способов, на основе которого надеюсь вы сможете определить какой подходит именно вам.
Составление семантического ядра с помощью поисковых систем
Поисковые системы Яндекс, Google, Rambler собирают статистику по тому, что запрашивают пользователи и предоставляют часть этой статистики в открытый доступ. Вы можете посмотреть ее по следующим ссылкам:
- http://wordstat.yandex.ru
- http://adwords.google.com («Отчёты и инструменты» --> «Инструмент подсказки ключевых слов»)
- http://adstat.rambler.ru/wrds/
В чем разница между ними?
- Яндекс по умолчанию показывает широкое соответствие, включая и подзапросы. Т.е. он объединяет запросы в разном падеже (например, «семантическое ядро» и «семантического ядра», без кавычек), также он плюсует к ним ключевые слова, которые содержат искомый запрос (например, он сложит данные по запросам «семантическое ядро» и «подбор семантического ядра», без кавычек). Как с этим бороться? Можно поставить запрос в кавычки – в этом случае он откинет словоформы (второй пример выше) и будет показывать количество запросов по ключевому слову и всем его падежам и склонениям. А можно также поставить перед каждым словом в запросе восклицательный знак «!» - в этом случае яндекс откинет и падежи и будет показывать только точное вхождение того запроса, который вы зададите.
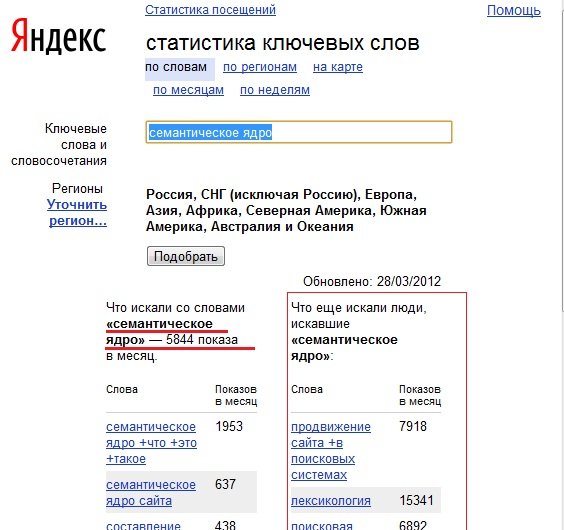 Яндекс также в правом столбце показывает запросы, которые искали вместе с заданным ключевым словом. Этот столбец позволяет значительно расширить семантическое ядро за счёт смежных запросов. Также в Яндексе Вордстат можно отслеживать тренды по месяцам или по неделям, можно ограничить поиск конкретным регионом страны или мира.
Яндекс также в правом столбце показывает запросы, которые искали вместе с заданным ключевым словом. Этот столбец позволяет значительно расширить семантическое ядро за счёт смежных запросов. Также в Яндексе Вордстат можно отслеживать тренды по месяцам или по неделям, можно ограничить поиск конкретным регионом страны или мира. - У Гугла все проще. Он тоже показывает широкое соответствие, но чтобы посмотреть на точное, достаточно в левом столбце поставить галку напротив пункта «Точное». Особенностью этого сервиса Google является то, что значения по запросам округляются. Точных запросов вы здесь не узнаете.
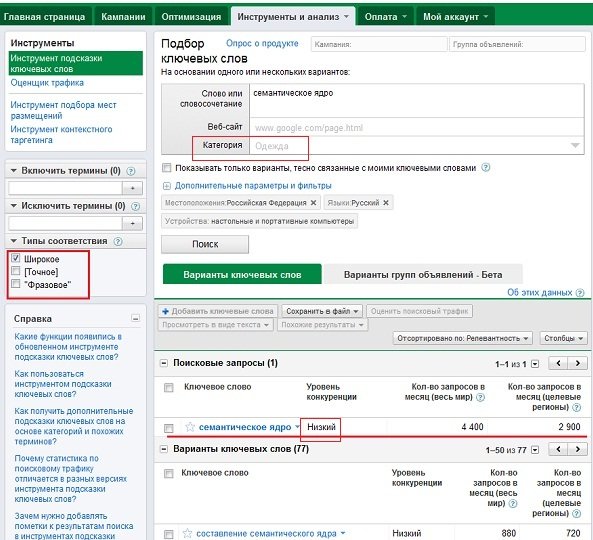 У сервиса Гугла также показывает оценочный уровень конкуренции для каждого ключевого слова. Кроме того сервис Google «Инструмент подсказки ключевых слов» позволяет узнавать набор ключевых слово и количество запросов для них для конкретной категории. Также как и в Yandex Wordstat, этот сервис можно уточнять региональные данные. Правда, здесь они ограничены конкретной страной. Детализации до региона Google не предоставляет.
У сервиса Гугла также показывает оценочный уровень конкуренции для каждого ключевого слова. Кроме того сервис Google «Инструмент подсказки ключевых слов» позволяет узнавать набор ключевых слово и количество запросов для них для конкретной категории. Также как и в Yandex Wordstat, этот сервис можно уточнять региональные данные. Правда, здесь они ограничены конкретной страной. Детализации до региона Google не предоставляет. - Рамблер с одной стороны самый точный. Он сразу показывает точное количество запросов по ключевому слову. Но с другой стороны он и наименее посещаемый из всех поисковиков и оценить реальное количество запросов во всем рунете по его статистике сложно.
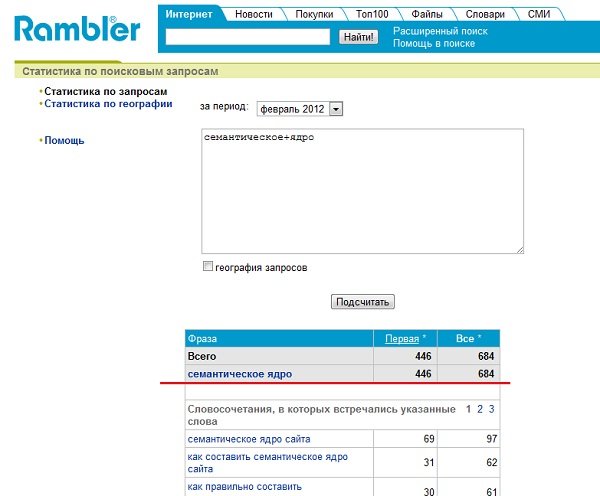
Эти данные, предоставляемые поисковиками, фактически являются исходными данными для всех программ и сервисов, описанных в следующих пунктах. Т.е. это своего рода первоисходник данных. Но надо учитывать, что и он содержит не все ключевые слова. В единицу времени запросов к поисковым системам делается огромное множество, базы данных не могут обнавляться в режиме реального времени.
Бывает, что вы видите в статистике сайта, что к вам приходили по какому-то ключевому слову с поисковиков, вбиваете его в один из вышеприведенных сервисов (или во все), но он вам показывает, что за месяц было 0 запросов. Что это? Ошибка поисковика? Ошибка вашей статистики? Ни то и ни другое. Просто это либо новый запрос, которого раньше не было в базе поисковиков, либо поисковик просто не занес его - и такое бывает. Т.е. на самом деле самые реальные данные - это статистика посещаемости вашего личного сайта. Намекаю. Обращайте особое внимание на вашу статистику. Единсвтенный ее недостаток - ее неполнота. Но дополнить ее можно и другими способами.
Отдельным пунктом для дополнения семантического ядра могут быть, например, поисковые подсказки Яндекс и Гугл. Но их можно собрать лишь специализированным софтом. Об этом я расскажу в третьем пункте статьи.
Подбор семантического ядра с помощью конкурентов
Семантическое ядро можно составит с помощью открытых статистик конкурентов. Как это делается?
Способ 1.
- Составляете список конкурентов.
- Ищите у кого из них установлен счетчик LI (Liveinternet) с открытой статистикой. Должна быть открыта статистика «по поисковым фразам» (есть и другие способы достать статистику из liveinternet, но это уже тема отдельной статьи).
- Экспортируете информацию со страницы «По поисковым фразам» по каким ключевым запросам посетители заходят на сайт.
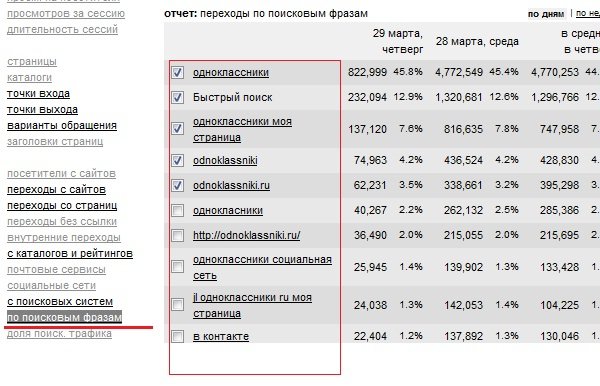
Недостаток этого способа: получаем множество запросов, которые надо отбирать и сортировать руками. Статистика LI содержит все запросы, по которым переходят на сайт, включая совершенно неподходящие для вашего сайта. На примере вверху это, например, запрос "jl одноклассники ru моя страница". По такому запросу конечно можно продвигаться, но поисковики не очень любят, когда текст оптимизирован под подобные запросы или запросы с опечатками, например.
Способ 2
- Составляете список конкурентов.
- Идете в сервис megaindex.ru на страницу анализ сайтов.
- Вбиваете каждого из конкурентов и выкачиваете список запросов.
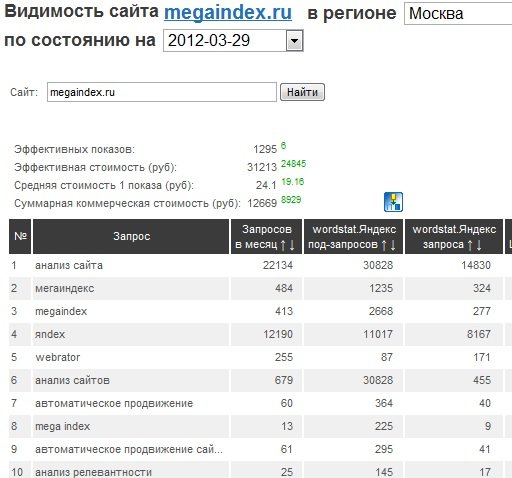
Сервис Мегаиндекс хорош тем, что предоставляет множество дополнительной информации по каждому из запросов, в том числе из сервисов яндекса и гугла. Также здесь, мне показалось, меньше хлама в результатах, как следствие меньше ручной работы по отбору ключевиков.
Способ 3
- Составляете список конкурентов (или начальный список ВЧ запросов, на котором будете основывать свое СЯ).
- Идете в сервис semrush.ru.
- Выбираете в качестве источника данных русскую базу по Google.
- Вбиваете адрес конкурента и видите кучу полезной информации, которую можно экспортировать.
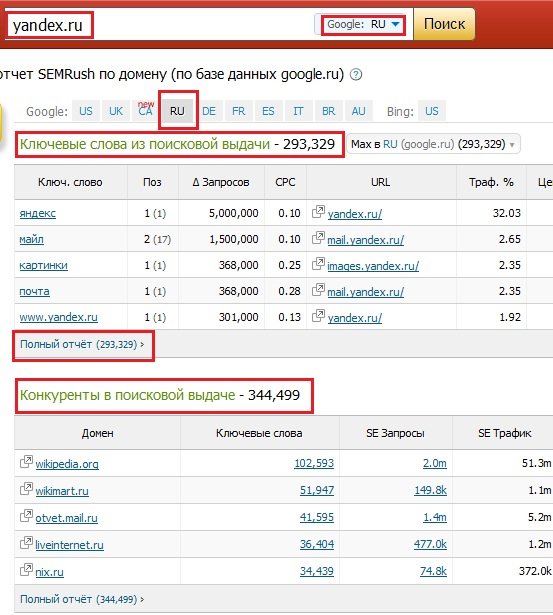
Особенностью сервиса является то, что данные здесь собираются и предоставляются только по поисковой системе Google. Также сервис очень полезен для подбора семантического ядра для англоязычных (и не только англоязычных) сайтов. Здесь можно составлять СЯ не только по сайтам конкурентов, но и по конкретным ключевым словам, как мы это делали с Яндекс Вордстат и аналогичными сервисами от других поисковиков. Недостатки Semrush:
- Сервис платный (тарифы от 70 до 150 долларов в месяц. На бесплатном аккаунте можно видеть только первые 10 результатов из каждого отчета. Тем не менее, довольной часто бывают промо акции и если вам удастся заполучить где-нибудь купон на semrush, то вам дадут две недели расширенного использования сервиса. Если же вы хотите купить тариф, я вам могу только позавидовать, значит вам действительно надо выкачивать информацию в промышленных масштабах.
- Данные могут быть устаревшими, т.к. непонятно, когда именно была собрана эта статистика и как давно она обновлялась. Тем не менее, данные вполне можно использовать, т.к. при подборе СЯ важны не столько абсолютные показатели, сколько относительные.
Есть также множество других сервисов, например pr-cr.ru, seolib.ru , webeffector, seopult, rookee и т.д., но я ими не пользовался и пока сказать о них ничего не могу.
Базы данных и программы для составления семантического ядра
Большой популярностью пользуются программы по составлению семантического ядра:
- KeyCollector – очень мощный инструмент. Собирает данные из wordstat.yandex.ru, Google Adwords, из агрегаторов webeffector, seopult, rookee, megaindex. Также она собирает информацию по поисковым подсказкам.
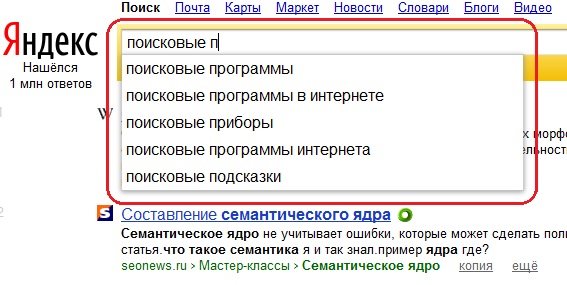
- Словоеб – если я не ошибаюсь, то именно с этой программы начинался KeyCollector. Фактически это очень сильно урезанная версия КейКоллектора.
- AmazingNicheFinder – это программой я пользуюсь иногда. Аналог KeyCollector правда с меньшим функционалом. Но основные функции – подбор количества запросов с wordstat.yandex.ru, с adwords.google.com, подбор количества конкурентов выдаче – программа выполняет. Также она может собирать количество морд и упоминаний ключевика в title у сайтов из топ10 по запросу.
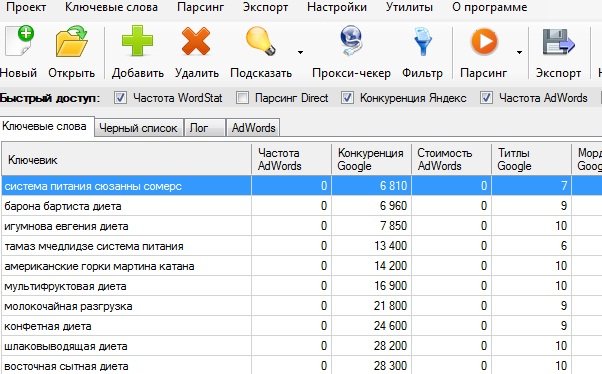
- Базы Пастухова. Фактически это оффлайн аналог Semrush и Megaindex в одном флаконе. Плюсы: условно одним кликом можно получить огромный объем данных для семантического ядра.
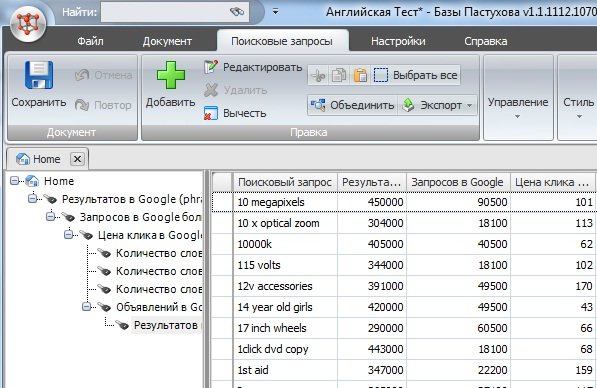
Минусы: высокая цена, возможно устаревшие данные. Хотя опять таки повторюсь – важны не точные абсолютные данные, а относительные. Ключевые слова в семантическом ядре надо сравнивать между собой и выбирать наиболее подходящие.
Есть и другие программы для составления семантического ядра, но опыта использования их у меня нет. Здесь я привел наиболее популярные из них. У всех этих программ есть один несомненный плюс - они позволяет делать не только подбор семантического ядра, но и расчитывать KEI, т.к. в дополнение к семантическому ядру собирают множество другой полезной информации. О том, что такое KEI я расскажу вам в другой статье.
Еще один способ составить семантическое ядро
Ну и еще один способ - это заказать составление семантического ядра на стороне, тем, кто обладает какими-нибудь из вышеперечисленных программ, имеет аккаунты на платных сервисах или просто имеет достатоную компетенцию, чтобы собрать данные из бесплатных источников. Последнее - это самое важное в подборе СЯ.
В рамках марафона, в котором участвует этот блог, я попал под раздачу на условно бесплатное составление ядра от seoenergy.org. Почему условно бесплатное? Потому что в ответ мне надо разместить заметку об услугах компании и поставить на них ссылку, чем я сейчас и занимаюсь J
Что могу сказать о результатах их работы?
Для начала мне необходимо было предоставить ВЧ запросы, урл сайта (т.е. нашего блога), стоп-слова, пожелания. Это я и сделал. В пожеланиях попросил подобрать СЧ и НЧ запросы по заданному списку ВЧ запросов и разделить какие по мнению специалистов seoenergy являются СЧ, а какие НЧ.
Результат мне прислали довольно быстро, буквально в течении пары дней. В результирующей таблице было порядка 600 запросов вместо обещанных 200. Это радует. Тем не менее, некоторых ключевых слов заданных в исходном задании, присланное СЯ не содержало. Это не радует.
Помимо непосредственно количества запросов (широких и точных) по Yandex Wordstat в таблице было приятное дополнение в виде оценок ведущих агрегаторов (webeffector, seopult, rookee) по предполагаемому трафику, если я попаду в топ3 и бюджет по продвижению, видимо тоже в топ3.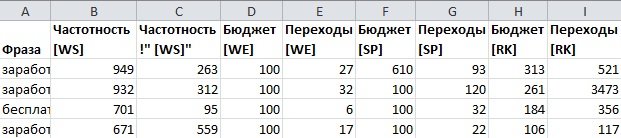
Чего не хватает по моему мнению в отчете?
- количество конкурентов в выдаче Яндекса и Гугла. Без этих данных отчет выглядит явно неполным. Для построения KEI (об этом термине в отдельной статье) эти данные крайне важны.
- все ключевые слова были сложены в один столбик, не было разделения по ВЧ, которые я задал вначале. Т.е. в присланной таблице нельзя было взять и быстро отобрать хвост для конкретного ВЧ запроса. Было б удобно, если бы добавили еще один столбец, в котором бы указывали ВЧ для подобранного СЧ и НЧ запросов.
- не было разделения на СЧ и НЧ, о котором я просил. Но это и не очень важно, т.к. во-первых, это дополнительная хотелка, а во-вторых, попросил я ее просто, чтобы проверить компетенцию сотрудников seoenergy и чтобы понять могут ли они проводить более глубокий анализ, кроме простого подбора ключевиков.
На этом я статью закончу, хотя писать о семантическом ядре можно еще очень и очень долго. Способов его составления, анализа и расширения существует огромное множество. Каждый имеет какой-то свой индивидуальный подход. Если вы составляете семантическое ядро каким-то другим способом, который здесь не описан – напишите, пожалуйста, об этом в комментарии. Мне будет очень интересно ознакомиться с ним.














