Что такое KEI и как его рассчитать?

Аббревиатура KEI в SEO раскрывается, как Keyword Effectiveness Index. Если перевести, то получим – индекс эффективности ключевых слов. Что же это за индекс, от чего он зависит и как его рассчитать? Рассмотрим все эти вопросы более подробно.
На начальном этапе создания сайта вы подобрали семантическое ядро. В результате получили огромный (или не очень) список ключевых фраз. Как определить, под какое из них желательно писать статью в первую очередь, под какое во вторую, а какие лучше оставить совсем на потом?
Самый лучший вариант: отранжировать, полученные ключевые фразы по значимости. А поможет нам это сделать - индекс KEI. Этот индекс зависит от уровня конкуренции по каждой ключевому фразе и от уровня трафика, который мы можем по нему получить (от количества запросов в месяц).
Очевидно, что чем больше запрашивают ключевое фразу в поисковых системах, тем больше трафика мы можем по нему получить, тем выгодней нам эта ключевая фраза (тем выше должен быть KEI). Это с одной стороны. А с другой стороны, чем больше конкурентов по ключевой фразе, тем сложней нам пробиться в топ и получить тот самый трафик (тем ниже должно быть KEI).
Классическая формула расчета KEI и мой вариант расчета
KEI был придуман Самантой Рой. Она придумала следующую формулу:
KEI = P2/C
P – это число поисков ключевой фразы в поисковике за последние 60 дней (популярность).
С – это количество сайтов, которое оптимизировано под эту ключевую фразу.
Таким образом, чем больше популярность, тем больше KEI, тем больше трафика по ключевой фразе мы получим, тем интересней она нам. Чем больше конкуренции, тем меньше KEI, тем сложнее будет продвинуться в топ, тем менее интересна нам данная ключевая фраза. Т.е. с ростом популярности KEI тоже растет, с ростом конкуренции KEI падает.
Но я для себя использую немного упрощенный вариант:
KEI = p2/u.
p – это число поисков ключевой фразы в поисковике за последние 30 дней (обратите внимание беру данные не за 60 дней, а за 30 дней).
u – это количество страниц (а не сайтов, как у Саманты), которое оптимизировано под эту ключевую фразу.
Рассмотрим каждый параметр более подробно.
Количество запросов ключевой фразы к поисковой системе в месяц (p) – это те самые цифры, которые мы получаем с помощью wordstat.yandex.ru, adwords.google.com или adstat.rambler.ru.
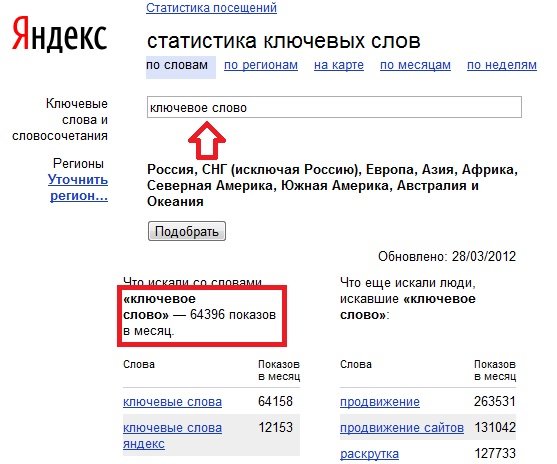
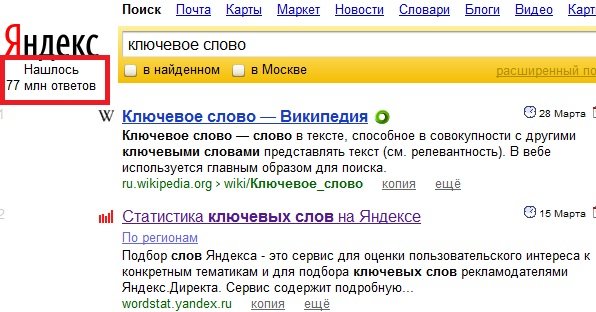
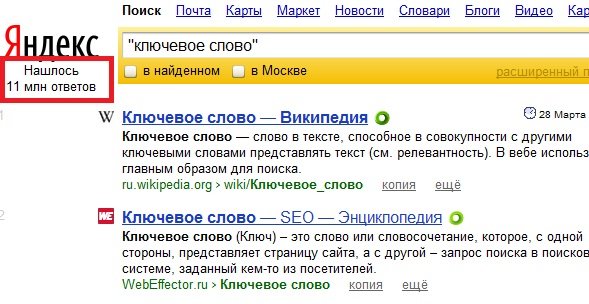
Количество страниц в поисковой выдаче по ключевой фразе – это фактически количество конкурентов, которые вам надо обогнать в поисковой выдаче, чтобы попасть на первое место по запросу. На рисунке ниже этот параметр выделен красной рамкой.
Здесь надо учитывать, что, как количество запросов к поисковику по ключевой фразе, так и количество конкурентов можно определять двумя способами:
- Широкое соответствие – показано на рисунках выше.
- Точное соответствие – показано на рисунках ниже.
Напомню, что широкое соответствие включает в себя все словоформы заданной ключевой фразы в разных падежах и числах («ключевое слово», «ключевые слова», «ключевого слова» и т.д.) и все словосочетания, которые содержат искомый запрос («подбор ключевого слова», «анализ ключевых слов» и т.д.).
Точное соответствие показывает, как это ни странно, именно точное количество вхождений заданной ключевой фразы. Для определения точного вхождения по количеству запросов надо ставить его в кавычки и перед каждым словом ставить восклицательный знак («!ключевое !слово»).
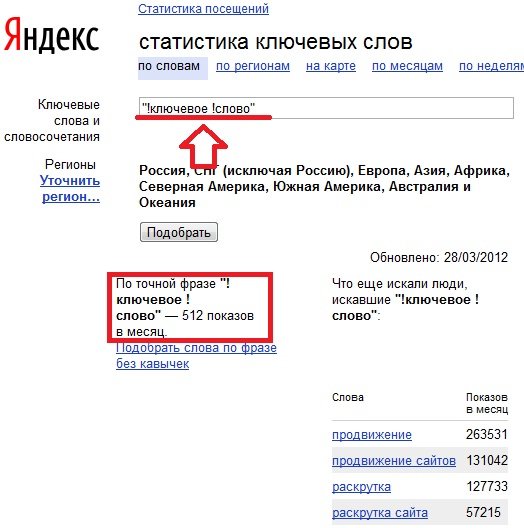
Для определения количества конкурентов при точном вхождении надо просто брать запрос в кавычки («ключевое слово»).
Здесь надо помнить, что:
- если конкуренцию вы рассчитываете с помощью точного вхождения, то популярность (количество запросов к поисковой системе) вам тоже желательно рассчитывать по точному вхождению.
- конкуренцию и популярность поисковой фразы имеет смысл определять для одной и той же поисковой системы. Т.е. определение конкуренции для яндекса, а популярности по рамблеру тоже будет иметь смысл, но будет уже менее показательным, если и то и другое расчитывать для яндекса, например. Ну и уж само собой внутри одного семантического ядра KEI для всех ключевых фраз должны быть расчитаны по данным из одних и тех же источников.
Вариации расчета KEI
Приведенная выше формула от Саманты Рой имеет несколько вариаций. Одну из них, ту которой пользуюсь я, я привел выше.
Но некоторые включают также в формулу параметры, от которых может зависеть ранжирование страницы или сложность продвижение в поисковой выдаче. Например, можно включить в формулу:
- количество главных страниц в топ10
- количество вхождений ключевой фразы в title на страницах в топ10
- средний PR (Page Rank) страниц (или сайтов) в топ10
- среднее количество ссылок, ссылающееся на страницы в топ10
- среднюю посещаемость сайтов в топ10 (например, по Alexa Rank)
- средний возраст доменов в топ10
- наличие доменов из топ10 в Яндекс Каталоге или в dmoz
- присутствие в топ10 сайтов гигантов (например, википедия или амазон, ебей для буржунета и т.п.) или наличие в топ10 колдунщиков яндекса.
- И т.п. и т.д.
Общее правило такое: т.к. все эти параметры усложняют попадание в топ, то все их надо ставить в знаменатель формулы для KEI. Также каждому из них можно дать свой весовой коэффициент, т.к. влияние их на сложность продвижения может быть совершенно разной.
Но я бы не рекомендовал вам так усложнять формулу. На самом деле ваша задача не определить сложность продвижения в топ10, а отранжировать ключевые фразы из семантического ядра между собой. Понять какие из них более просто продвигать и при этом вы получите по ним больше трафика, а какие сложней продвигать и трафика по ним будет не так много.
Т.е., с помощью KEI вы определяете относительную ценность той или иной ключевой фразы в вашем конкретном семантическом ядре.
Примеры расчета KEI
Рассчитаем, таким образом, KEI для вышеприведенных примеров.
По широкому соответствию будем иметь:
p = 64 396
u = 77 000 000
KEI = (64 396*64 396)/77 000 000 = 54. Обратите внимание, точное значение нам расчитывать здесь не обязательно. Я округлил до целых, максимум сколько я брал для себя - это тысячные. Зависит от того насколько широкий диапазон KEI у вас получается для вашего семантического ядра.
По точному соответствию будем иметь:
p = 512
u = 11 000 000
KEI = (512*512)/11 000 000 = 0,024. Здесь я взял цифру до тысячных, т.к. при округлении до целых получится 0, что совершенно не показательно.
Хорошие это цифры или плохие? В сети часто мелькает такая шкала:
- KEI до 10 — плохие ключевые фразы.
- KEI от 10 до 100 — хорошие ключевые фразы, с наличием трафика.
- KEI от 100 до 400 — отличные ключевые фразы, которые позволяют получать значительную долю трафика.
- KEI больше 400 — ключевые фразы высшей категории с мега-порциями трафика и большим количеством аудитории.
Я бы не рекомендовал ей пользоваться, т.к. во много KEI зависит от ниши, в которой вы работаете. Есть ниши,где клюевиков с KEI>400 очень мало. Есть ниши, где в принципе мало ключевиков и эта шкала не имеет смысла.
Еще раз повторюсь, что KEI нужно рассматривать только в рамках целого семантического ядра, чтобы определить какое клювое слово важнее (имеет бОльший KEI), а какое менее важно (имеет маньший KEI).
Как рассчитать KEI?
Основные способы на самом деле описаны в статье про подбор семантического ядра. Краткая выжимка:
- Вы можете рассчитывать KEI вручную, собирая информацию о популярности поисковых фраз и уровне конкуренции из поисковых систем.
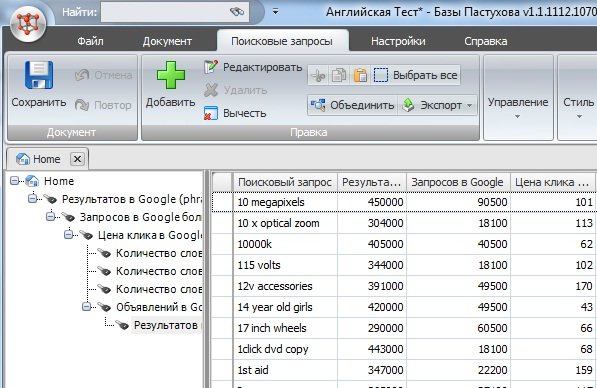
- Вы можете рассчитывать KEI из уже собранных для вас баз ключевых слов (базы Пастухова, например).
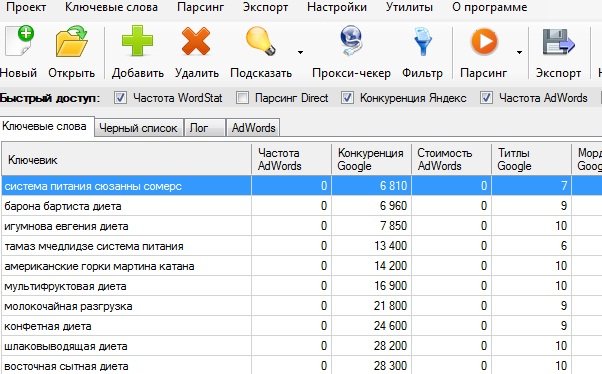
- Вы можете рассчитывать KEI с помощью купленных программных средств. Лучшим на сегодняшний момент является Key Collector. Я пользуюсь Amazing Niche Finder. Так уж сложилось исторически и мне его вполне хватает.
Если у вас есть какие-то комментарии и уточнения – не стесняйтесь, спрашивайте, всегда будем рады вам ответить.